Since JavaScript allows most native methods to be overwritten I was wondering if it’s possible to speed up an application by adding caching to native methods.
This post will look at the idea and see if it’s possible to achieve performance improvements in this way.
Wrapping the native function
If you look at the code below you’ll notice it’s inefficient. (Since this is just a demo we don’t actually use the return value of the replace call.)
"aa".replace(/[a-z]/g, "z") // "zz"
"aa".replace(/[a-z]/g, "z")
"aa".replace(/[a-z]/g, "z")Rather than doing the replace operation three times we should do it once and then re-use the result.
We could do that by storing the result in a variable:
var res = "aa".replace(/[a-z]/g, "z") // "zz"
res
res
resBut our goal in this post is to provide an automatic way to avoid repeating the replace operation.
We can replace the native String replace function with a memoized version. That means we store the return value for a particular set of parameters in a lookup table. When the function is called again with the same parameters we return the cached value, rather than re-doing the replace operation.
var cache = {}
var nativeStringReplace = String.prototype.replace
String.prototype.replace = function(search, replacement){
// `this` is the string ("aa")
// search is the regular expression (/[a-z]/g)
var cacheKey = this + search.toString() + replacement
if (!cache[cacheKey]) {
cache[cacheKey] = nativeStringReplace.apply(this, arguments)
}
return cache[cacheKey]
}(This function sometimes caches a little over-optimistically, so it would break some applications. For example, it will wrongly attempt to cache when the replacement argument is a function.)
Now this code will only result in one call to the native replace function:
"aa".replace(/[a-z]/g, "z") // "zz"
"aa".replace(/[a-z]/g, "z")
"aa".replace(/[a-z]/g, "z")After running the code the cache object will look like this:
{
aa/[a-z]/gz: "zz"
}
The key consists of the string replace is called on ("aa"), the regular expression used to match the part of the string that should be replaced ("/[a-z]/g"), and the replacement ("z").
Measuring the performance impact
Let’s figure out what the performance benefit of this optimization is.
Rather than runnning the operation once we’ll run it 100 thousand times. First using the native replace function, then with memoization enabled.
console.time measures how much time it takes to run the replace operations.
console.time("Native")
run()
console.timeEnd("Native")
// Overwrite `replace` function as shown above
// ...
console.time("Cached")
run()
console.timeEnd("Cached")
function run(){
var r = /[a-z]/g
var str = "aa"
for (var i=0; i<100000; i++) {
str.replace(r, "z")
}
}This is the result in the console:
Native: 44ms
Cached: 76msThe optimization is slowing the code down!
It turns out that in this case the overhead of generating the cache key and looking up the cached value takes more time than doing the replace operation again.
But the cost of the replace operation will depend on the size of the string that we operate on. We can use Array(101).join("a") to generate a longer string with 100 “a” characters.
function run(){
var r = /[a-z]/g
var str = Array(101).join("a")
for (var i=0; i<100000; i++) {
str.replace(r, "z")
}
}Now the results are different:
Native: 345ms
Cached: 91ms
With memoization enabled, replace calls only require a constant time lookup. Without it, every replace call takes an amount of time that grows with the length of the string
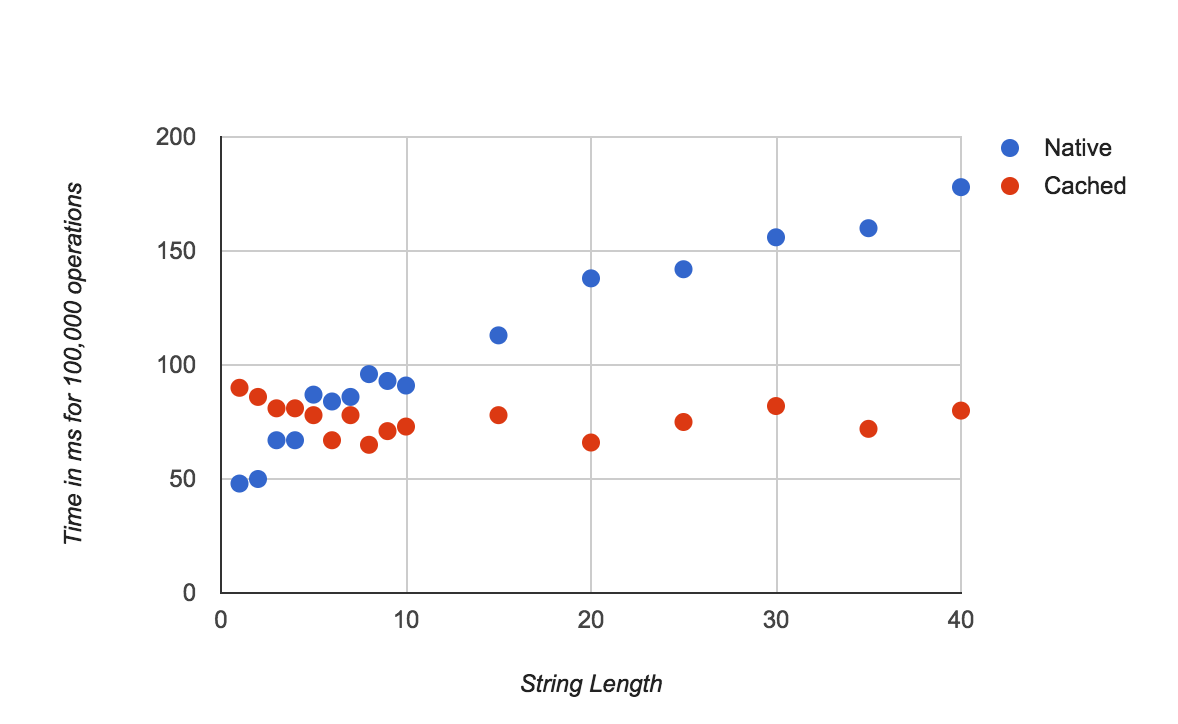
Is it useful?
The example above is extremely artificial. It assumes that a meaningful amount of time is spent in operations that have been done before in exactly the same way.
In practice, I’ve not been able to speed up a real application measurably.
To make this useful, one would have to identify native functions that are both expensive and likely to be called several times with similar parameters.
