FromJS is a dynamic dataflow analysis tool for JavaScript. That means it collects data while your program is running, and can then use that data to answer questions about your program.
For example, it can tell where an object’s properties were assigned. If you look at a string it can show you the code where that string was generated. You can inspect the DOM and it will tell you where the data in the UI was loaded from.
I’m working on FromJS 2 now which will be a whole lot less bad than FromJS 1. This post explains how it works.
Rewriting JS with Babel
In order to capture how data flows through an application each value needs a corresponding tracking value. If the code we’re analyzing is var a = 5 then the tracking would look something like this:
var str = "a", str_t = {type: "stringLiteral"};I use a custom Babel plugin to make those kinds of transformations to the JS source code. The example above would actually be compiled to this:
var str = __op(
"stringLiteral",
{
value: ["a", null]
},
),
str_t = __getLastOperationTrackingValue();Instead of running the code directly every operation is an __op function call. You call __op("stringLiteral") to create a stringLiteral, or __op("binaryExpression") to do a two-parameter operation like adding two numbers.
The operation sets a tracking value which we can access later and assign to str_t.
Operations also have arguments, in this case just one argument called value. Each argument is an array with two items. The first item is the actual argument value, the second item is the tracking value.
The code for all of this is currently in a giant operations.ts file. Each operation has a visitor (a term used by Babel when transforming the code) and an exec function to actually perform the operation at runtime.
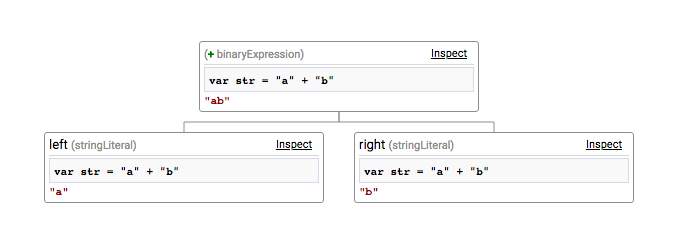
Here’s the transformed code for var str = "a" + "b"
var str = __op(
"binaryExpression",
{
left: [
__op(
"stringLiteral",
{
value: ["a", null]
}
),
__loT()
],
right: [
__op(
"stringLiteral",
{
value: ["b", null]
}
),
__loT()
]
},
{
operator: "+"
}
),
str_t = __loT();We can then draw str_t as a tree that looks like this:
Intercepting requests with a proxy server
To collect data for a page with FromJS all code loaded by that page needs to be processed by the Babel plugin described above. This is done by passing all requests through a proxy server.
I currently use Puppeteer for testing. The FromJS proxy server runs on port 8081.
puppeteer.launch({
args: ["--proxy-server=127.0.0.1:8081"],
headless: false
});To intercept HTTPS requests you need to install a root certificate for the proxy.
FromJS 1 used a Chrome extension to intercept requests, but it was very hacky since Chrome doesn’t provide the necessary APIs. (Instead the extension cancelled the original request and then injected the code directly.)
Tracking data collection
Loading a page generates a lot of tracking data - every single JavaScript instruction creates more data to keep track of! Chrome crashes easily when pages run out of memory, so this data is sent to a local backend server. (For now I just store it in memory or write it down in a massive JSON file.)
Here’s an example tracking value for the a+b operation. The tracking values for the left and right arguments are referenced by ID.
{
index: 278868536,
stackFrames: [
" at eval (http://localhost:11111/eval1798295553.js:1085:11)"
],
operation: "binaryExpression",
result: {
length: 2,
type: "string",
str: "ab",
primitive: "ab",
knownValue: null
},
args: {
left: 278868534,
right: 278868535
},
astArgs: {
operator: "+"
},
extraArgs: {}
};
I removed it from the JSON above, but I’m also storing the location of the operation in the source code right now. Ideally that isn’t needed since I have the call stack in stackFrames, but right now the source maps generated by Babel aren’t working (because of my plugin). And debugging source maps is tricky.
Analyzing the data
So we’ve collected a bunch of data, but it’s not very useful unless we analyze it somehow.
Mostly I’ve been working on inspecting a string and seeing how it was constructed. Each character comes from somewhere and we can find out where.
For example, if we have a simple todo app Vanilla TodoMVC we can inspect the HTML of each todo item and see its origin. In the example below the todo item was loaded from localStorage.
However, I’d love to hear in what other use cases you can think of!

Is this the right way to build this?
I think ideally this would be implemented at the browser/JS engine level. This would be more performant, and it would be possible to return a tracking value directly from native functions like string.replace.
Also, a lot of data is collected but never used. Time travel featues like in ChakraCore or SpiderMonkey might be able to help with that.
So, why use JavaScript?
- I know JavaScript well, and it’s more accessible to other JS devs too
- No problems with merging upstream changes from the forked JS engine/browser
But I’m hoping that one day someone will build a better version of this 🙂.
Status of FromJS 2
I’m hoping to have a version you can install and use on most websites by August 2018. I’ve you’re interested you can subscribe on fromjs.com.
